There’s a recurring pattern in the WordPress world: a client reports that their site is slow. The specialist dives into profiling, analyzing database queries, trimming plugins. Hosting? Left untouched. After all, you should optimize what you have before throwing money at hardware.
Sounds reasonable - and in many cases it is. But there’s a line beyond which this approach becomes fundamentally wrong.
That line is where a server returns multi-second TTFB on a simple business site - Gutenberg, 7 plugins, no WooCommerce, no Elementor - without any caching.
A site like this on a decent host should achieve a TTFB of 200-300 milliseconds with zero caching. Google considers 800ms the acceptable threshold. I wouldn’t even raise an eyebrow if TTFB hovered around 800-1200ms - for many, that’s still an acceptable trade-off relative to cost.
But 3-4 seconds? That’s several hundred percent above the norm. And no amount of code optimization will fix it.
A Ticking Time Bomb
Let’s say you manage to squeeze decent results out of such a host using cache. The site loads, the client is happy.
But you’ll never reach a 100% cache hit ratio.
And once the optimization process wraps up and ongoing oversight disappears, it only takes one of the following to bring the whole thing crashing down:
- A new traffic channel with URL parameters that the cache doesn’t ignore
- A new plugin or plugin update that conflicts with the cache configuration
A few months later, the site owner might launch an expensive ad campaign, and instead of getting cached pages, visitors wait 4 seconds per load.
The campaign has an absurd bounce rate because of one small oversight.
The entire optimization investment - wasted. Because underneath it all, there’s still a terrible server.
My Data - Same Code, Two Servers
I recently took on the optimization of a WordPress site. It was sitting on a weak host, so from the very beginning I made it clear: there’s no point investing in code optimization if we leave the site on this server.
We agreed on a migration to proper hosting, and in the meantime I handled the optimization on a dev environment. Once it was done, I ran benchmarks on both environments - to get hard data.
Results on the Old Host
Old theme (before optimization):
Times (TTFB, no cache): 2.16s, 2.55s, 2.52s, 2.52s, 3.47s, 4.14s, 4.24s, 2.93s, 2.90s, 2.61s, 2.89s, 2.36s, 2.44s
Average: 2.90s
New theme (after optimization):
Times: 2.29s, 2.15s, 2.85s, 3.45s, 2.52s, 2.28s, 2.64s, 3.72s, 2.43s, 2.33s, 2.47s, 2.13s
Average: 2.61s
10% faster. Still 326% above the recommended TTFB threshold.
Query Monitor showed nearly a full second faster than the cfOrigin header from Cloudflare. In Query Monitor, the difference in database query times was clear - the optimization was clearly working. But the LiteSpeed server added so much overhead that the whole effort translated to a modest 10% improvement with still terrible results.
Be honest - would you pay a developer for a day and a half of work for that kind of progress? I wouldn’t.
Results on the Target Host
Same theme versions, same code - but on a proper server.
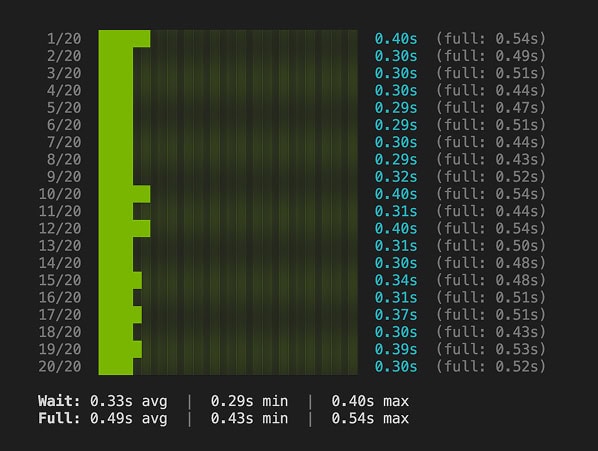
Old theme on the new host:
New theme on the new host:
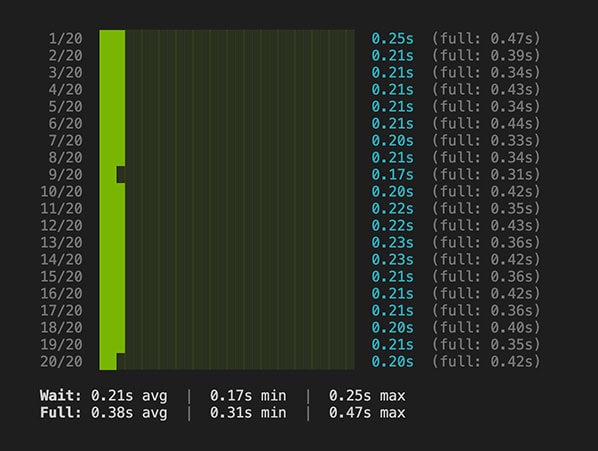
In addition to full TTFB, I also measured the server’s wait time - how long the server actually spent processing the request: PHP + Nginx.
Full TTFB: 0.38s vs 0.49s
Server wait time: 0.21s vs 0.33s
22% improvement and TTFB with over 400ms of headroom below the recommended threshold.
If we strip out connection time and focus on the PHP + Nginx processing alone, the server delivers the page 36% faster.
That looks a bit better than 10% and times above 2.5s.
Foundation First, Optimization Second
Only after confirming real improvements do I move on to configuring cache.
Because even if I can’t predict every scenario - it’ll still be fine.
I also know that even a logged-in user (who won’t get a cached page) will be able to use the site quickly and comfortably.
Back to the Numbers
Let’s look at this from a business perspective.
If the old server could routinely add a full second of overhead (measured as the difference between Query Monitor timing and cfOrigin), then even investing hundreds of thousands and rewriting the application from scratch, we wouldn’t come close to matching the old theme version served from a better host.
You’re always limited by that one second of terrible web server overhead.
Sometimes it’ll be better, sometimes worse - but by trying to save on proper infrastructure, you can end up in an endless loop of development work that never reaches a happy ending.
And if you flip the order?
Migration alone improves performance from 2.90s to 0.49s. That’s nearly 6x faster.
Zero code analysis.
Zero refactoring.
One quick migration to a good host.
One day - and you have your result.
The costs may look higher if you compare hardware price lists side by side.
But if you factor in developer time, the migration alone might turn out to be far cheaper.
Stop Tolerating Bad Hosting
Years of price wars and dirty tricks in the hosting market have led to a situation where people accept as fact that hosting can be cheap and slow. And they just live with it.
That’s just how WordPress is!
We look the other way and try to mask it with cache. And that’s a straight path to making WordPress look like a joke as a platform.
Look at it from the perspective of a business considering WordPress for a new project.
Imagine a decision-maker stumbles upon an optimization course and sees that to make a simple business website reasonably fast on WordPress, they need to hire a performance specialist and dedicate three months to the process.
What do you think they’ll do?
Choose WordPress, or go with Astro, Next.js, or any other technology where this problem simply doesn’t exist?
By accepting this status quo, we as WordPress developers are shooting ourselves in the foot.
We normalize performance pathology and teach clients that “this is just how it works.” And then we wonder why WordPress is losing market share.
Of course, we should always strive for good design patterns and solve problems at the design stage - not patch them later when the site is already tanking.
But if the starting point of our project exceeds acceptable norms by hundreds of percent due to bad infrastructure, it’s our responsibility to draw a clear line and say: stop.
Let’s stop tolerating this.
This is exactly the thinking behind SHIFT64 - because I believe solid infrastructure should be a foundation, not a luxury.